Introduction
“Comma-separated values” is a widely used file format for tabular data storage, where each row represents a record and each column a field that is contained in that record. The format is known as CSV because commas are used to divide the values. Reading and Writing CSV in Bash is a widely used data format that can be used to transfer data between many platforms, applications, and programs. It usually takes the following format:
col1,col2,col3
val1,val2,val3
val1,val2,val3
val1,val2,val3
Many professionals who work in sectors like system administration, software development, and data analysis frequently deal with CSV files. Proficiency in reading and writing CSV files inside a Bash environment is crucial for task automation and effective handling of substantial data sets.
We’ll examine many approaches to reading and writing CSV files with Bash in this post. We’ll go over the many tools that are available and give usage examples. This tutorial will give you the knowledge you need, regardless of your level of familiarity with Bash, to handle CSV files in your shell scripts.
Reading CSV in Bash:
We’ll now look at how to use tools found in a Bash environment to extract data from a CSV file.
Here’s an example of reading a CSV file with awk and extracting the data:
# Read the CSV file
while IFS="," read -r col1 col2 col3
do
# Do something with the columns
echo "Column 1: $col1"
echo "Column 2: $col2"
echo "Column 3: $col3"
done < input.csv
Writing CSV in Bash:
Using the echo command to divert its output to a file rather than the regular output pipe is one of the easiest ways to write CSV files in Bash. For instance:
#!/bin/bash
# Write data to the CSV file
echo "column1,column2,column3" > output.csv
echo "data1,data2,data3" >> output.csv
echo "data4,data5,data6" >> output.csv
Using the echo command to divert its output to a file rather than the regular output pipe is one of the easiest ways to write CSV files in Bash. For instance:
Free eBook: Git Essentials
Check out our hands-on, practical guide to learning Git, with best practices, industry-accepted standards, and an included cheat sheet. Stop Googling Git commands and actually learn it!
Another option for writing CSV files in Bash is to use printf. The printf command provides more control over the output format and is often used when writing to a file. For example:
#!/bin/bash
# Write data to the CSV file using printf
printf "column1,column2,column3\n" > output.csv
printf "data1,data2,data3\n" >> output.csv
printf "data4,data5,data6\n" >> output.csv
In this example, the header row and data rows are written to the output.csv file using the print command. At the conclusion of each row, a newline character is added using the format string.
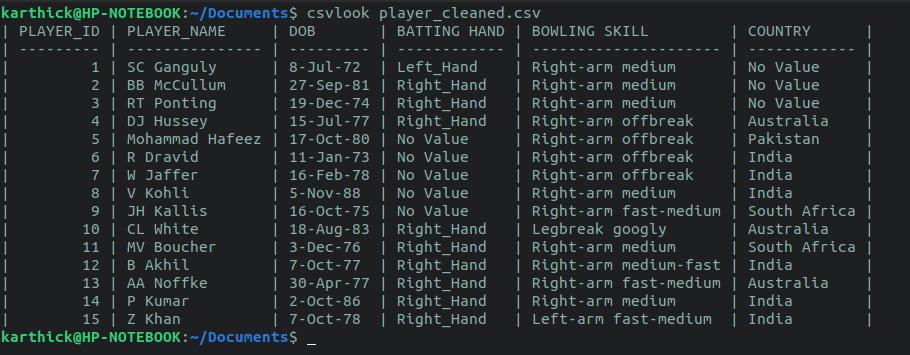
Example 1: Read the Original Content of the CSV File:
Create a Bash file with the following script that reads the full content of the “customers.csv” file using the “while” loop:
#!/bin/bash
#Set the filename
filename=“customers.csv”
#Read each line of the file in each iteration
while read data
do
#Print the line
echo $data
done < $filename
The following output appears after executing the script:

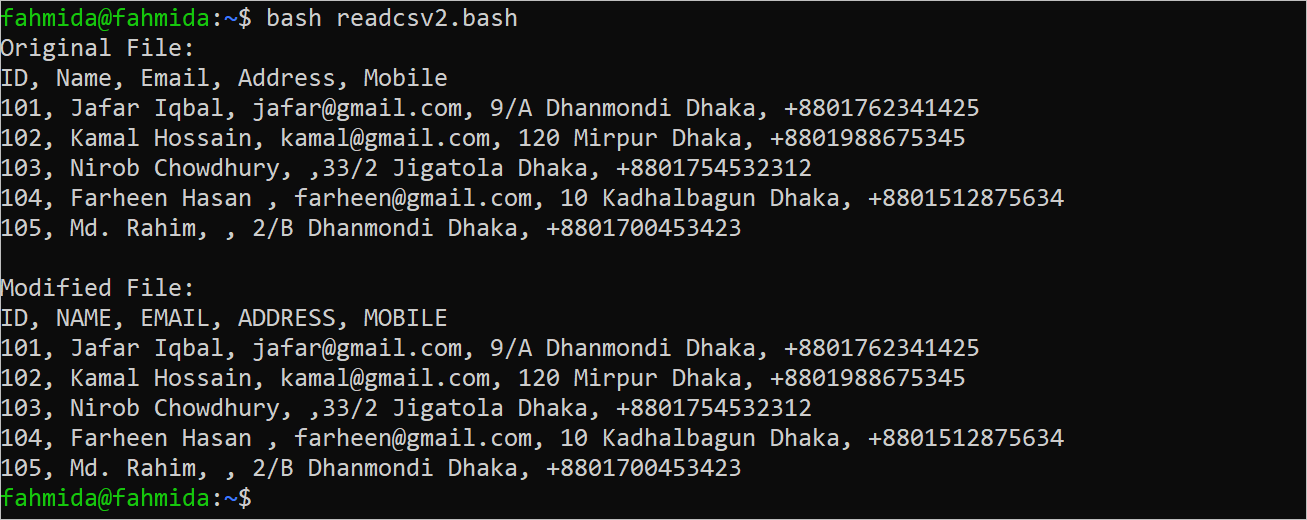
Example 2: Read the CSV File by Capitalizing the Header:
printf “Original File:\n“
#Print the original content of the CSV file
cat cstomers.csv
#Create a new CSV file after capitalizing the header
awk ‘BEGIN{FS=”,”;OFS=”,”}
{
if(NR==1)
print toupper($0)
else
}’ customers.csv > updatedcustomers.csv
printf “\nModified File:\n“
#Print the new CSV file
cat updatedcustomers.csv
The following output appears after executing the script:
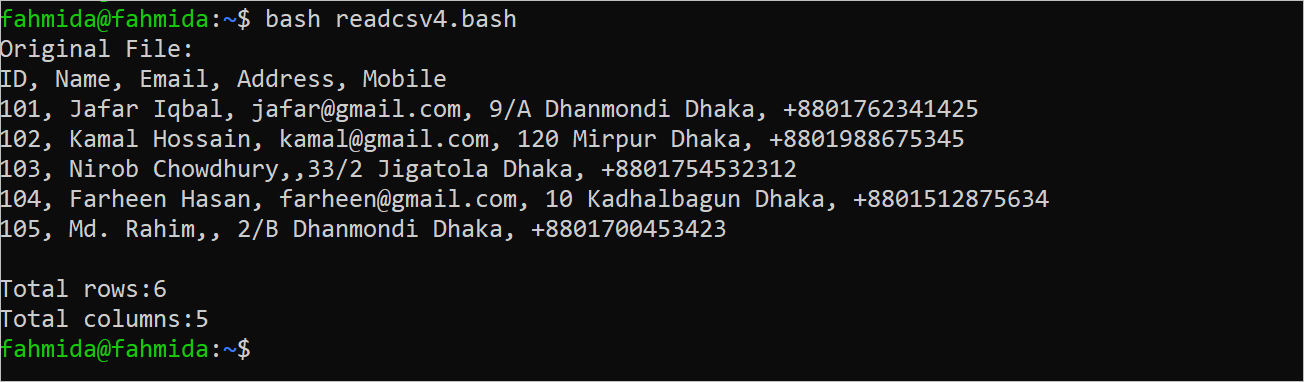
Example 3: Print the Total Number of Rows and Columns of the CSV File:
The following script, which counts the total number of rows and columns in the “customers.csv” file, should be created in a Bash file. The total number of rows in the file can be printed using the NR variable. The total number of fields in the file can be printed using the NF variable.
printf “Original File:\n“
#Print the original content of the CSV file
cat customers.csv
echo
echo -n “Total rows:”
awk -F, ‘END{print NR}’ customers.csv
echo -n “Total columns:”
awk -F, ‘END{print NF}’ customers.csv
The following output appears after executing the script. The total lines in the file is 6 and the total fields of the file is 5 which are printed in the output:
Conclusion:
In conclusion, working with CSV files in Bash can be simple and efficient. By using awk and echo commands, we can read and write CSV files without relying on external tools or libraries.
Come along with us to learn more about Linux.
stay on our website linuxhints.info
Get more information about
Printing from the Linux Command Line